
- ホーム
- 進行中の研究
- 今までの研究
- 出土簡牘の生態的研究
- 額済納現地調査2009
- 額済納現地調査2013
- 居延漢簡調査
- 「肩水金関漢簡による漢代西北交通・防衛機構の研究」(青木俊介)
- 「周縁領域からみた秦漢帝国の総合的研究」(高村武幸)
- 「新出簡牘資料を用いた戦国秦から統一秦にかけての国制変革に関する研究」(渡邉英幸)
- 「最新史料に見る秦・漢法制の変革と帝制中国の成立」(陶安あんど)
- 「中国古代における 家族と「移動」の多角的研究─静態的家族観からの脱却をめざして─」(鈴木直美)
- 「三国呉・長沙の年齢史─人生の諸段階と同居家族」(鷲尾祐子)
- 「五一広場東漢簡牘よりみた後漢時代の在地社会」(飯田祥子)
- 中国古代簡牘の横断領域的研究(1)
- 中国古代簡牘の横断領域的研究(2)
- 中国古代簡牘の横断領域的研究(3)
- 中国古代簡牘の横断領域的研究(4)
- 資料庫実験室
- 研究仲間
- 史料ノート
資料庫実験室
趣旨説明
我々の研究班は十年以上も文書簡牘の共同講読を重ねてきた。お互いを大いに刺激し合うことはいうまでもなく、史料講読の成果は、メンバーの著作物にもその形を現わしている。しかし、講読の知見をいつでも簡単に参照できる共有財産として保有することは実に難しいことである。
簡牘が行政文書の主要な書写材料、ひいては情報管理ツールとして国家による行政運営や社会統制を支えていた春秋戦国から魏晋までの時代は「簡牘の時代」とも言えるが、この簡牘時代を通じて文書簡牘の出土は比較的均等な分布を示しており、総量は20万枚を優に超えている。その中で、メンバーの研究重心はそれぞれ異なるから、より複眼的な講読が可能になる一方、共有財産の形成も一層複雑な問題を孕むことになる。
近年は、共著の電子書籍を手掛けるようになったことをきっかけに、この問題をより切実に痛感するようになり、いきおい輪を広げて、メンバーか否かを問わず、関心のある方が誰でも利用できる文書簡牘資料庫を構築しようのではないかという考えが芽生えた。ここでは、長年講読の中心に置かれていた里耶秦簡を例に、資料庫構想に関わる実験を新しい順に公にし、今後の総合的なデータベースの構築に備えたいと思う。
正直に言えば、今までは情報学的には失敗の連続である。我々は簡牘のマニアで、情報学の専門家ではないから、やむを得ない面もある。また、博物館などのように、所蔵資料を売りに、資金や専門家を集め、大々的に宝を世に送り出す力もない。一文無しの手ぶらで今からとんでもない財産をつくっていく、そうした気持ちで、まず素直に失敗から学ぶことにしたい。
ここで公開する著作物やデータやスクリプトは何れも、他の表示がなければ、クリエイティブ・コモンズ 表示-非営利 4.0 国際 パブリック・ライセンス(https://creativecommons.org/licenses/by-nc/4.0/)の範囲でご自由にお使いください。また、一緒に学びたい方や、この知的ベンチャー企業に情報学的知見を投資したい方は大歓迎である。関心のある方は、管理者の陶安あんど(ejina@duck.com)までご一報ください。(本文の文責も、異なる注記がなければ、全て管理者の陶安にある。)
9 TEI試作品――校訂情報02(製作中)
8 TEI試作品――走馬楼呉簡吏民簿TEIテキスト化試案(2024年12月14日公開)
簿籍は、我々の従来の文書様式分類では最も手薄な分野であるが、走馬楼呉簡は、ほぼ全ての簡が簿籍で占められるという特徴を持つ約8万点の簡牘の資料群である。この資料の研究に長年従事してきた鷲尾祐子氏は、走馬楼呉簡の吏民簿を対象に、『四年小武陵郷簿』の電子テキスト試作品を作成し(xml形式の電子テキストのスキーマはtei_all_ja.rncに格納)、関連の諸考察を「吏民簿TEI化について」という報告レジュメ(docx、pdf)に纏めた。
鷲尾報告は改めて我々が日頃の資料講読に当たり注目する情報の多様性を印象付けることとなった。時間的な制約もあり、研究会では簿籍のTEI化方針を定めるには至らなかったが、TEI規格の面白いところは、一部の比較的簡単なタグを先行して付与していくことが可能であることである。たとえその中に「間違った」タグがあるとしても、系統的に同じ「間違い」を繰り返していけば、タグ付けの最終的な方針が決まった時に、機械的にそのスキーマに合うタグに置き換えることができる。
言い換えれば、極めて初歩的なタグ体系でTEI化を実践し、経験を蓄積することができる。鷲尾報告はそうしたことを実証してくれたと言える。同様な実践を継続しつつ、今後は、テキスト校訂・形態記述・様式分類・語彙等というように、情報類型を分け、徐々にタグ体系を構築していく予定である。
7 TEI試作品――校訂情報01(2024年10月3日公開、同年10月14日訂正と補記、同年10月29日再補記)
6 索引データの再分析で述べた情報復原の苦労を避けるために、今後はテキスト情報を最初からTEI規格に準拠して明確にエンコーディングしていく所存である。簡牘学に適したTEIスキーマを構築するには、如何なる情報を蓄積していくかを予め見極める必要があるが、そうしたモデリングは、頭の中で考えるだけでうまくいかないものであるから、まず幾つかの試作品を作成し経験を積んでおきたい。
9月21日に開催した研究会では、校訂情報と簿籍とに関わる試作品を取り上げ議論を行ったので、まず校訂情報に関わる部分を本実験室の第7弾として公開する。……展開する/折りたたむ
校訂とは、古文献学においても、古文書学においても、根本資料であるテキストを構築する上で不可欠な作業であり、紙媒体の時代でも繰り返しなされてきた歴史がある。電子テキストの作成に当たり、従来蓄積されてきた情報を継承する必要があるから、まず紙媒体時代において、如何なる情報が如何なる形で記述されてきたかを確認しておきたい。
伝統的な校訂においてなされてきた情報処理は大きく二つの層に分かれる。一つには、原本とされるテキストを記述するレイヤがある。原本が仮想のテキストに過ぎない場合も珍しくないが、実在するか否かを問わず、そのテキストを、記述することを通じて再現することは多分に解釈的作業であり、テキストに様々な変更を加えることになる。もう一つの層は、原本とされるテキストを記述した諸テキストの比較である。それは、異なる背景を持った校訂者が異なる環境で行ったテキスト記述によって生じた諸種の変更を比較することになる。つまり、テキストの「版本」もしくはバージョンの比較にほかならない。
ここでは、まず前者に注目する。従来簡牘学において簡面に記されたテキストが如何に記述されたかを振返り、それが電子テキストにおいても失われないように、そこに込められた情報が如何なるタグで正確に記述できるかを考察する。出土文書よりも出土文献の方が、記述される対象が単純であるのみならず、古文献学の方が、テキスト記述に重きを置いてきたように思われるので、出土文献から分析を始めたい。
具体的には、まず筆者が古文献学的整理を担当した嶽麓秦簡の『為獄等状四種』に寄せた凡例を手掛かりに、従来原本の記述が如何になされ、各記号に如何なる意味が込められたかを見極め、その含蓄をそれぞれタグに翻案してみた。それは、報告レジュメの「実習:校訂用タブ01」(docx/pdf)である。そうした既存情報をできるだけ機械的にTEIテキストに継承していきたいから、次に、関連タグの自動付与を試みた。タグ付けを行うスクリプトは、TEI-Encoder(shakudoku01).pyであり、元のテキストデータはIgokutojo(Zenjoho).txtに収められている。自動付与の出力結果に手動でTEIのヘッダーを付けたxmlファイルは、Igokutojo(Shisakuhin01).xmlからご参照ください。
なお、データが基づく所の拙著『嶽麓秦𥳑《爲獄等狀四種》釋文注釋(修訂本)』(上海古籍出版社,2021)では、校訂の記述情報を二つの異なる釈文に分散して掲載していた。二つの釈文はIgokutojo(Hyoten).txtとIgokutojo(Hakubun).txtに入っており、Igokutojo(Zenjoho).txtは、この二つのファイルを、手作業のコピペ・正規表現による置換およびaddOrPunctuation.pyを用いて纏めたファイルである。
補記(10月14日)
異なるテキスト・エディションの機械的比較処理に向けたプログラミングの過程において、TEI-Encoder(shakudoku01).pyの改良バージョンであるTEI-Encoder(shakudoku02).pyが副次的産物として得られたので、エディション比較スクリプトに先立ち、それを簡単な説明と共に公開しておく。
エディション比較スクリプトの基本的な発想には、エンコーディングされたテキストのエレメント数を、白文のままの釈文の文字数に揃えた上で、白文釈文におけるいわば「植字的」(typographical)転写の違いと、通常釈文における読み換え等の解釈的(lexical)違いを分けて処理する考えがあった。そのために、より正確なエンコーディングが必要になったが、それを実現すべく、pythonの本来の強みであるオブジェクト指向型のプログラミング技術をより積極的に活用することにした。
より具体的に言えば、今まで本ページにおいて公開してきたスクリプトは何れもコンピュータに命令を渡していくプロセスに則して書かれたいわゆるプロセス指向型のスクリプトであった。その場合には、プロセスの各段階において自ら必要な情報などを個別の変数などに格納して管理する必要が生じる。それに対し、オブジェクト指向型のプログラミングでは、何時か必要になる情報などを予め属性などとしてオブジェクトの中に取り込んでおく。オブジェクトの雛型として、「クラス」を定義しておき、その中に必要な属性やファンクションを含めておく。雛型として定義したクラスに則った特定のオブジェクトを初期化してコンピュータに渡せば、その先の情報管理はコンピュータが自動的にやってくれるので、プロセス指向型プログラミングと比べて負担が大きく軽減される。
スクリプトの仕組みについては、スクリプトの中で詳細な説明を附したので、ここでは省略する。クラス・通常のファンクション・タグ情報は、スクリプト本体と別のファイルに収め本体で呼び出すようにしてあるので、お使いの際は、以下の四つのスクリプトを全てダウンロードして同一のフォルダに格納する必要がある。(TEI-Encoder(shakudoku02).py、classes.py、tools.py、tags.py)
同スクリプトに釈文データを渡すには、前回のファイルの僅かな誤字を訂正したIgokutojo(Zenjoho)02.txtを用い、得られた出力結果はoutput(TEI-Encoder(shakudoku02))Text0.xmlというファイルである。前回と同様に、手動で適宜ヘッダーを付けた。
なお、本スクリプト作成にあたり、次の文献を参照した。
再補記(10月29日)
TEI準拠のタグ付けは、機械可読性の獲得を目的とする。将来様々な機械処理を行う予定であるが、まずタグ付け自体の検証を行う必要があり、それにも機械処理の力を借りることができる。そのために、XSLTという言語を用い、前回のTEI-Encoder(shakudoku02).pyの出力結果として得られたoutput(TEI-Encoder(shakudoku02))Text0.xmlをもう一度テキストファイルに戻してみた。タグを別の言語で機械的に処理して得られるテキストファイルが、タグ付けの入力に用いたテキストファイルと一致すれば、タグが元の情報を正確に記述したことが証明される、というのがこの試みの背後にある考え方である。テキストファイルの比較は、多くのテキストファイルエディタが自動的にやってくれるので、こちらの仕事は、XSLTのスクリプトを書き、実行するだけである。
XSLTとは、eXtensible Stylesheet Language Transformationsの略で、自らXML形式のマークアップ体系を持ちながら、種々のプログラミング要素を兼ね備えた特異な言語である。変数の書き換えや単純なループ制御も許容されず、徹底した脱プロセス指向型の言語であるから、慣れるには少し時間は掛かったが、結果的にkoseiyou(zenjoho).xslとKoseiyou(Hakubun).xslという二つのスクリプトで、output(TEI-Encoder(shakudoku02))Text0.xmlをKoseiyou(zenjoho).txtとKoseiyou(Hakubun).txtとに変換することができた。両ファイルは、今回意図的に省いた出土記号情報などを除けば、元の釈文を正確に再現していることが確認できたので、今回の実験は成功したといえよう。
ただ、Igokutojo(Hyoten).txtの復原はより多くの困難を伴った。その原因は次のように考えられる。つまり、重文記号の処理に当たり、文字自体の解釈と重文記号の解釈とが複雑に絡み合い、プロセス指向型スクリプトの影響を引きずっている現行のタグ体系ではXSLTによる処理に限界があるためである。少し技術的な話にはなるが、重文記号の記述においては、テキストノードとエレメントノードとが不規則的に入れ混じっているため、XSLTでは、表示と不表示を取捨選択する基準となる要素の一部に正確にアクセスできない。
ところが、もう少し掘り下げてみると、この問題は、TEIのタグ体系における省略記号の扱いとも深くかかわる。例えば、『為獄等状四種』簡124に見える「建﹦等﹦(建等,建等)」という表現は今回TEIのタグ体系に準拠して次のように記述してきた。
原文表記の「建﹦等﹦」は、「<abbr>」というエレメントに、それを解釈して展開した「建等,建等」は、「<expan>」というエレメントに収められている。「<abbr>」にはテキストノードとして記述される原文の「建」と「等」は、「<expan>」の中にも、全く同じくテキストノードとして含まれている。つまり、元の原文表記については、「<abbr>」と「<expan>」とに同一の情報は二重に記述されている。それにはそれなりの合理的な理由はあるが、このこと自体は情報学的禁じ手と言わざるを得ない。
この情報学的禁じ手がIgokutojo(Hyoten).txtの復原において禍して情報読み取りを困難にするのは、原文釈読と原文解釈とに関する付加情報が「<abbr>」と「<expan>」という二つのエレメントに分散して記述されるからである。例えば『為獄等状四種』簡134に実際に見える「肆﹦室﹦(肆、室。肆、室)」という表現にはさらに原文釈読に関わる疑問を表す「?」と文脈による釈読を表す「&」(通常は囲い文字)が加わり、それが「肆(?)﹦室&﹦(肆、室。肆、室)」という形をとるとしよう。その場合、記述は
となる。「肆」と「室」の文字情報は重複して「<abbr>」と「<expan>」の両者に見えるのに対し、釈読と解釈に由来する付加情報は分離して示されている。Koseiyou(zenjoho).txtでは、二種の情報は同様に分離して示され、Koseiyou(Hakubun).txtでは、一種の情報しか参照されないから、XSLTによる変換には全く支障がないが、Igokutojo(Hyoten).txtでは、「肆(?)、室&。肆、室」というように、文字情報の重複を解消しつつ、二種の付加情報を同一の原文表記の上に纏めることになるから、XSLTによる処理が極めて困難になる。つまり、「<abbr>」と「<expan>」のどちらが一方の文字情報を無視しつつその中に不規則的に配置されている付加情報を他方の文字情報に結合しなければならないという難題が生じる。
文字情報の重複は、まだ比較的容易に避けられる。<abbr>エレメントを削除し、原文の釈読に関する情報を<expan>のテキストノードに直接に挿入し、重文記号に関する情報を収めた<am>をそのまま<expan>に持ち込めばよい。
最初に試してみた時には、TEIガイドラインにおいてこういうことが許容されることに、少し驚いたが、なるほど、ガイドライン作成においては、このような細かい問題に対してまできちんと考察と対応がなされたと感心した次第である。しかし、それでも、前述の「建﹦等﹦(建等,建等)」の例と比較して分かるように、<expan>および<ex>が含むテキストの文字数は句読点などの影響で不規則的に変化する。そのため、<am>に含まれる付加情報を正確に<ex>の中の対応する文字に関連付けることは依然として困難を伴う。バージョン比較においても、テキストノードをより正確に制御する必要があるので、この問題は宿題として次の第8弾の実験に持ち越すこととする。
なお、校正の過程で、元の釈文ファイルが拙著の公開釈文と異なる箇所が幾つか散見されたので、Igokutojo(Zenjoho)02.txtを手動で訂正したIgokutojo(Zenjoho)teiseiban.txtを作成した。今後のタグ付け実験には、こちらのファイルを用いることとする。また、classes02.pyには、XSLTの正確な記述に必要になったため、タグに関するより詳細なドキュメンテーションを加えた。
今回のXSLT変換にあたり、次の文献を参照した。
6 索引データの再分析(2024年8月2日公開)
2 索引稿の編集で述べたように、『里耶秦簡(壹)索引稿』は、単なる単語の一覧ではない。同形語が識別できるように、また原文表記の揺れ等にも対応できるように、官職名や身分呼称の正規化表記を工夫し、原文と併記して掲げることにした。編集当時はまだよく分からなかったが、それは、実はテキストエンコーディングでいうインデクシング(indexing)において行う正規化(standardization)と全く同じ作業である。(#dariahteachのindexingやNames: People, Places and Organisationsをご参照ください)
そこで、テキストエンコーディングの実験を始める前に、まず我々が今まで無意識のうちに行った情報処理をもう少し詳しく調べてみたいと考えた。つまり、索引データを再分析し且つそれを釈文の元データと照合することを通じて、我々が語彙の次元で如何なる情報に着目してきたかを再確認し、さらにそれをどこまで機械的に処理できるかを実験してみた。今後のテキストエンコーディングの参考になると考える。……展開する/折りたたむ
データ加工の工程
釈文ファイルの予備的加工
まず、3 HTML形式の資料庫構想の下で作ったHTML形式の釈文ファイルをより処理しやすいテキストファイルに作り替え、手動で貼り付けたリンクを削除した。そのためには、またPerlスクリプトを使用した。shakumonyomidashi.plは、釈文ファイルから、各簡(簡面)に関わる様式分類・配列情報・簡番号・釈文のみを抽出し、shakumon.txtに格納する。linkdeleter02.plは、さらにshakumon.txtでは釈文に混じっているリンクを自動的に削除し、その結果得られる情報をshakumon(linknuki).txtに出力する。リンクの削除と同時に、画像として貼り付けていた外字も一旦、文字として認識できる「{A+B}」の形式に戻した。3 HTML形式の資料庫構想では、まだ関連情報をワードファイルで管理しつつ手動で対応する画像を貼り付けていたが、外字情報を手動でgaijiichiran.txtに移し替え、linkdeleter02.plに読み込ませて、「{A+B}」形式の文字列としてshakumon(linknuki).txtに書き込ませた。
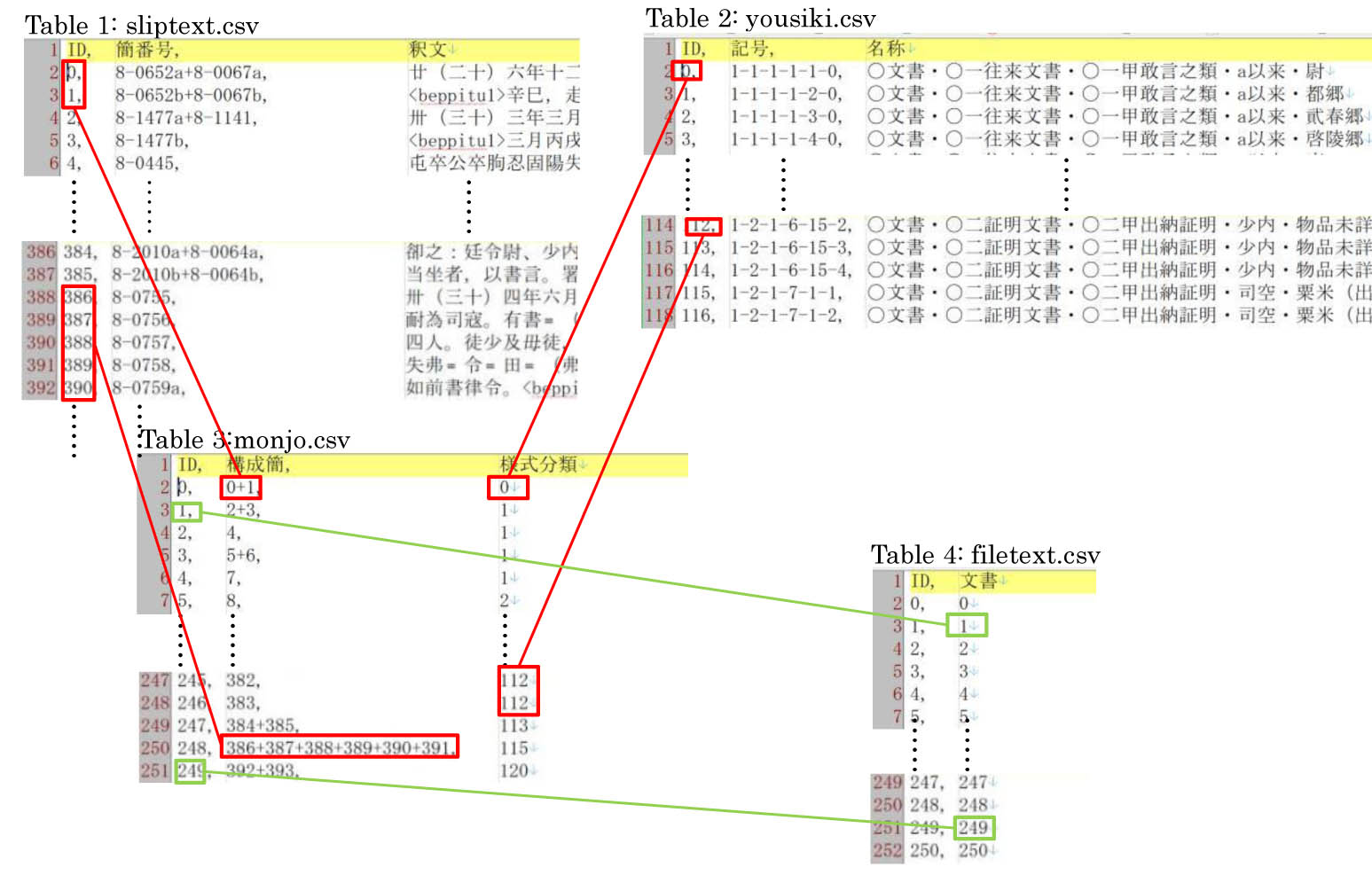
shakumon.txtとshakumon(linknuki).txtは、機械可読性を具えたテキストファイルであり、各レコードは、数字で始まる様式分類・配置情報・簡番号のテキスト外情報と、釈文のテキスト情報から構成される。下図は、より見やすいように、リンク情報のないshakumon(linknuki).txtの構成を示すイメージである。

機械可読性を検証するために、この釈文ファイルをPythonスクリプトのRDBcreator.pyで読み込み、CSV形式で出力し、小さなRDBを構成する四つのテーブルに自動変換させてみた。得られたCSVファイルは、sliptext.csv, monjo.csv, yousiki.csv, filetext.csvである。(なお、yousiki.csvに見える各様式の名称は、1 ワード形式の訳注稿の様式分類一覧(yoshikibunrui.xlsx)を参照して手動で注記した。)
RDBの構造は下図の通りである。一つの簡面に記されているテキスト(sliptext)は、明確な外縁をもつ物理的現象といえるが、それが単独で文書を構成するのか、他の簡面と合わせて一つの文書を構成するかは、我々の観察すべき多様な出来事である。monjoのテーブルはそうした簡面の出会いという出来事に対する観察結果をしめす。ID番号の0と1とが付せられた文書はそれぞれ簡面0と1もしくは2と3に記されており、ID番号248の文書は、386から370までの五枚の簡面に跨る。実際には、さらに一枚の簡面に複数の文書が記載されている状況も存在するが、里耶秦簡の場合、そうした状況は、密接に関連しあう文書に限られるから、それを便宜的に一つの複合文書と捉えた。そのために、特別な対応は不要となったが、今後テキストエンコーディングに移行する際はより原則的な処理方法を考案する必要がある。
次に、yousikiテーブルは、一つの様式類型を一つのレコードと捉えて示したものであるが、この様式分類体系は我々の長年の議論の結晶と言える。この分類を各文書に適用した我々の観察結果は、monjoのテーブルに様式分類のIDの形で含めておいた。最後に、我々は里耶秦簡として出土した簡牘を一つの文書資料群として理解するが、その相互関連性を様式分類および時間や内容的関連性という三つの要素に着目して一つの全体に復元したのが、1 ワード形式の訳注稿であり、3 HTML形式の資料庫構想の釈文ファイルであり、また、下図のfiletextのテーブルでもある。情報量は基本的に三者とも同じである。テーブルの方はもはや我々の肉眼には全く視覚的情報を与えないが、瞬時に他のテーブルも参照できるパソコンにとっては、こちらの方が処理しやすい。
もちろん、それを3 HTML形式の資料庫構想の下で作ったようなHTML形式のファイルに戻すことも瞬時にできる。htmlcreator01.pyはその仕事をしてくれるPythonスクリプトであり、リンク情報を含むshakumon.txtのデータを基に生成させたHTMLファイルはliya-shakumon(python).htmlである。ヘッダー等、釈文テキスト以外にHTMLファイルの構築に必要な情報は、headertojoho.zipに纏めた幾つかのテキストファイルに前もって収め、そこからhtmlcreator01.pyに読ませたが、釈文本文および各簡の配置を決める情報は、前述したshakumon.txtから機械的に読み取ることができる。
(ここを境に、スクリプトはPerlからPythonに替わる。Perlは以前AA研の言語学の先生から教わったが、今はPerlよりもPythonの方が多くの可能性を開いてくれるので、こうした実験をするうちに、Pythonに乗り換えた。Python学習に用いた文献は後掲の通りである。)
なお、この模擬RDBにおいてほとんどすべてのデータがきれいに連番に並んでいるのは、我々が手動で釈文ファイルという簡牘データの集合体の形を整えてから、それに基づいてRDBのデータを作ったためである。生データからRDBを構築してから釈文ファイルを自動生成させる場合には、連番の美しさが失われる代わりに、手動作業の痛みが和らげられるはずである。一方、手動でデータを作ったため、諸種の不整合性が生じている。例えば、我々の様式体系には県官の「田」と「田官」を正確に区別し、「〇一往来文書・〇一甲敢言之類・a以来・田」と「〇一往来文書・〇一甲敢言之類・a以来・田官」に「1-1-1-1-10-0」と「1-1-1-1-11-0」の記号を割り振っているのに、yousiki.csvには、たまたま訳注稿ではまだそうした認識に至っていなかったため、「1-1-1-1-10-0」は欠番となってしまった。ここでの目的は、技術の実験であるから、そうしたことはあまり問題にならない。実際にDBを運用する段になったら、手持ちのデータを機械可読なデータに変換する過程において、そうした不整合性を計画的に解消していかなければならない。そもそも、様式分類の類型記号として、HTML形式の釈文ファイルのアンカーを流用したことはとても乱暴なやり方である。それは、異なる次元の情報を一つの文字列に便宜的にまとめたものであるが、本来はもちろん情報次元ごとに独立したフィールドを設けるべきである。
一方、先述のPerlとPythonスクリプトによる読み込みに支障を来すほどの不整合性も多数見られた。例えば、釈文テキストの基本単位を、簡と簡面と文書のどちらかにするかを正確に決めていなかったため、テキスト情報をshakumon.txtに格納するshakumonyomidashi.plは、「釈読情報」と「読み下し文」へのリンクをテキスト単位の境として転用したが、そのリンクが欠落している場合は当然誤作動を起こす。そうした不整合性は、上記の加工過程において誤作動を起こす形で明確に現れたので、3 HTML形式の資料庫構想の釈文ファイルにおいて該当箇所を全て手動で訂正しておいた。
索引データの予備的加工
索引稿は、手動による校正を経て刊行したので、そのデータは2 索引稿の編集で紹介した元データのkanshokumeisakuin(narabekae).xlsxとはすでに大きく異なる。そのため、索引稿のPDFファイルから正確なデータを復元した。その結果得られた索引データは、indexdata(personal names).txt(人名索引)、indexdata(offices).txt(官職名索引)、indexdata(ranks).txt(身分呼称索引)、indexdata(labor).txt(労働編成索引)、indexdata(place names).txt(地名索引)、indexdata(dates).txt(暦日索引)に格納した。復原過程においては、環境依存文字が「懬→呟」「圂→卆」「〼→㽂」等のように文字化けを起し、また画像データとして挿入されていた外字も完全に失われてしまったので、それらを手動で補正した。また、余分な標題行の削除、簡番号の書式の整形等の作業は適宜正規表現を使って行い、旧字から新字への還元には、2 索引稿の編集で紹介したreplace.plのPerlスクリプトとokikaekomoku.txtの新旧字一覧を使用した。さらに、以下説明する加工工程において諸種の不整合性によって発見した索引稿の誤字・脱字等も随時訂正していったので、前記のデータファイルは、すでに公刊の『里耶秦簡(壹)索引稿』とも一定の出入りがある。
索引データの構造
索引データを機械的に読み込むには、その構造を正確に把握する必要がある。索引によって書式がやや異なるが、以下は官職名索引を例にとり、下図に従って索引データの構造を説明していく。

必要な時に索引稿と比較できるように、各データファイルには最低限のナビゲーションを残した。上図の「..あ」「..い」や「<145,0>」はそうである。半角の点を用いているのはたまたま筆者使用のテキストエディタの設定で、その行がアウトラインバーに表示されるからである。テキストファイルでも五十音ですぐにデータが見られるように、見出しとしてそれを残した。「<145,0>」の方はページ数である。データとしてはこうしたナビゲーション行は価値がないので、後述のPythonスクリプトでは、こうした行は「^[\.<]」という正規表現で検出し、処理から排除する仕組みにしてある。
次に、残りの行は、簡番号のある行と無い行とに分かれるが、無い行には、見出し語が掲げられている。「^([^\d]+)$」という正規表現で簡単に検出できるようにしてあるが、上図では「安陽(県)」「主(動詞)」「主(脇付け)」「令(県令)」「令(都官)」がそれに当たる。約束としては、見出し語は語の正規化した表記(「安陽」等)と全角括弧に囲まれた注記から構成される。正規化した表記とはこの場合、伝世文献等から知られる一般的な用字法に従った表記である。例えば原文ではよく「壊徳」や「競陵」と表記される県は、『漢書』地理志に従って「懐徳」や「竟陵」に改める。「貮春郷」と「貮郷」のように、原文表記に揺れが観察される場合には、最も一般的と推測される「貮春郷」に正規化表記を統一する。全角括弧の注記は補足説明ではあるが、同形語においては、それは、「つかさどる」という意味の動詞の「主」と、脇付けとして宛名の下に付せられる「主」というように、語を識別する働きをする。
データ行には必ず簡番号があり、番号の前には正規化表記、番号の後ろには原文表記が掲げられる。三者を区別するために、間にデリミタとしてタブ文字が置かれている。正規化表記が原文表記と一致する場合には、原文表記は省略される。上図においては見た目でやや不規則的に見えるが、それは、やはり正規表現(「^([^\t→←]+)\t([^\t]+)\t*([^\t]*)$」)で簡単に三種のデータを識別して抽出できる書式となっている。「→」は後述する参照項目にヒットしないように使われている。また、デリミタとしてタブ文字を用いているのは、たまたま筆者が習慣的にそうしているためであり、一般的な習慣に従ってコンマを用いるのも差し支えない。その場合には、三種の情報を取り出す正規表現を「^([^,]+),([^,]+),*([^,]*)$」に改めればよい。
正規化表記と原文表記とが異なる最も一般的なケースは、上図には例を掲げてはいないが、前述の「懐徳」や「竟陵」等である。以前はよく仮借や当て字と説明されたが、むしろ時代的・地域的或いは個人的用字法の変化や揺れと考えた方が実情に近い。出土文字資料研究では、通常「壊(懐)徳」や「競(竟)陵」のように釈文に表記する習わしとなっている。正規化表記にも全角括弧が使われるから、索引稿ではそうした原文表記における「読み換え」を意図的に避けた。正規化表記と原文表記に「懐徳」と「壊徳」とが並べられるだけでも、用字法の違いは一目瞭然である。正規化表記の方で全角括弧が使われるのは、編者の補足説明を挿入するためである。例えば、図の行5373には、簡8-0192a+8-0685a+8-0462の原文では、「令」とのみ表記されている官職名は、文脈から「大匠木功右校令」を指すことが判るので、正規化表記において暗黙の裡に了解される「大匠木功右校」を補った。同様に、行5と行7には、原文の「陽守」と「陽守丞」を「安陽守」と「安陽守丞」と解釈したので、全角括弧でそれを示した。
また、正規化表記と原文表記には、幾つもの違いがあるので、下表の通り纏めてみた。上図の例としては、行15には、簡8-0160+8-0363の「〼舎,夷陵獄〼治所」については、「【伝】舎,夷陵獄【佐/史某】治所」のように、簡の欠損によって失われた原文を墨付括弧で示して「【伝】舎,夷陵獄【佐/史某】治所」と補った。少しややこしい例としては、行2047と行2049の「尉、官主」と「司空、尉主」が挙げられる。それは、尉と県官もしくは司空と尉に当てられた文書の書出しにおいて「主」という脇付を用いた例であるが、主はもちろん「尉、官主」と「司空、尉主」の冒頭の「尉」と「司空」にも掛かる。「尉、官主」は「主」のほか、「尉」と「官」に重複して収録し、それぞれ正規化表記を「尉主」と「官主」とした。「司空、尉主」も、「司空主」と「尉主」として掲げた。
正規化表記に書き込まれている情報は、とても雑多な印象を与えるに違いないが、それこそ索引編集において無意識的に行った情報処理の主幹であるから、今後TEIエンコーディングにおいては、語彙のインデクシングのためにこれらの情報を正確に記述できるタグ体系を構築していかなければならない。
|
正規化表記 |
原文表記* |
|
|
通常字への置換 |
假御史謷 |
叚御史謷 |
|
漆園 |
䰍園 |
|
|
呼称完形の復原 |
尉史華 |
令佐華自言:故爲尉史 |
|
省略情報の復原 |
尉主 |
尉、官主 |
|
官主 |
||
|
(畜官)佐貳 |
佐貳 |
|
|
(治虜)御史 |
御史 |
|
|
御史(大夫) |
御史 |
|
|
(監)御史/御史(大夫) |
御史 |
|
|
同形語の識別** |
潁陰 |
潁陰 |
|
潁陰(令/長)相 |
潁陰相 |
|
|
畜官 |
畜官 |
|
|
畜官(嗇夫)適 |
畜官適 |
|
|
異種情報の削除 |
尉史郀般 |
尉史士五郫小莫郀般 |
|
逸失文字の推測補填 |
【傳】舍夷陵獄【佐/史某】治所 |
〼舍,夷陵獄〼治所 |
|
釈読者の注記記号の削除 |
安陽守 |
〖安〗陽守 |
|
畜官 |
畜(?)官 |
|
|
王宮 |
|
|
|
* 厳密には、ここでいう原文表記は、釈読者が原文を転写したとされる釈文のことをいう。 ** 多くは同形の官署名と官職名の違い |
||
索引データの読み込みと原文との照合
前述したデータ構造に従って索引データを読み込み原文と照合するためには、複数のPythonスクリプトを組み合わせてみた。もちろん一つのスクリプトに纏めても一向に差し支えないが、分かりやすくするためにも、また実はプログラミングもしやすくするために、データ加工をできるだけ多くの小さなファンクションに区切って実施した。プログラミングの面白いところは、通常人間の頭で一気にやってしまう情報処理を、より小さな根源的プロセスに分解し、順序を踏んでより正確に行えることである。
それぞれのファンクションについては、スクリプトの中で詳細な説明を附したのでここでは詳述を控えるが、基本的には、ファンクションを、データ読み込み・データ加工・その他のツールに分類し、それぞれinputmethods.py、dataprocessing.py、tools.pyに収め、indexdata.pyから呼び出し実行するようにしてある。
プログラミング言語には、必ずプログラムの実行の流れを制御する要素と、データを加工する要素がある。制御要素の方は、正直に言って我々情報学の素人が必要とする知識は高が知れている。「for」や「while」等のループ(一定の命令群を繰り返し実行させる仕組み)、「if」の条件文や、ファンクションの定義と呼び出し方さえ覚えてしまえば、すぐに驚くほど複雑な作業ができてしまう。我々がむしろ意を用いるべきはデータ加工の仕組みである。それには、正規表現と変数があるが、正規表現の方は一般的なテキストエディタで幾らでも練習できるので、変数の理解の方が実は我々のデータ加工のカギとなる。主要なものはinteger整数、string文字列、listリスト、dictionary辞書であるが、辞書のリストとか辞書の辞書等、複雑に組み合わせることもできるので、変数に対する理解こそが、我々素人でもプログラミングによるデータ加工ができるかどうかの分かれ目ではないかと感じる。
そこで、筆者は、一定の処理が終れば、必ずその結果をテキストファイルに出力させる習慣を身に着けた。indexdata.pyでは、十数個ものテキストファイルが出力されてしまい、誠に煩に堪えないが、データ構造がプログラムによって実際にどのように変更されたかがテキストファイルで簡単に確認できるようになる。最初は予想と全く違うものが出てくることが多いが、そこが学習の最大のチャンスなのである。
indexdata.pyの流れは次のフローチャートのように要約することができる。
.jpg)
それを簡単に説明すると、最初は、索引データ(indexdata(personal names).txt、indexdata(offices).txt、indexdata(ranks).txt、indexdata(labor).txt、indexdata(place names).txt、indexdata(dates).txt)を読み込み、暦日以外のデータを、見出し語および項目・参照項目の一覧に作り替えた。lemmata,items,refitemsの三つのリスト変数がそれに当たるが、各リストには、正規化表記と原文表記とが、随時参照できるように対応付けられている。原文データ(Liya-shakumon(linknuki).html)も、釈文ファイルから読み込み、簡番号からアクセスできるsliptextという辞書に格納しておく。次に、索引データを釈文データと同様に簡番号からアクセスできるように、slipnodicという辞書に作り替えた上で、釈文データの原文書式に合わせた索引データの原文表記をその辞書に追加する。それは、索引と釈文ファイルとで、原文表記の仕方が異なり、釈文データとの照合を可能にするため統一する必要があるからである。釈文ファイルの原文表記において関連語彙を正確に認識するために必要な情報は、索引データの正規化表記と原文表記に分散して含まれているから、それを検索可能な形で釈文形式の原文表記に加えていく。これはstringprepというファンクションの働きである。この原文形式の原文表記に、lemmataのリストから得られた見出し語の通し番号を名前とするタグをtagprepとtaggingという二つのファンクションで付けていく。これによって始めてタグによって構成語を正確に記述する原文表記が得られるが、索引間で語の取り方が異なるため、収録文字列にはやや不規則的な重複が見られるから、このステップに移る前に、重複を可能な限り除去する。これはindexdataconsolidationというファンクションの働きである。また、タグ付けのためにstringprepを通じて書き込んだ付加情報は、釈文ファイルの原文と異なるから、タグ付け後それをstringprepremovalで再び削除していく必要がある。このように、複数の加工工程を経て得られた索引データのタグ付けされた原文表記を使って、sliptext辞書に収められた釈文データの中の該当文字列を置き換えていく。それで、タグ付けされた下図のような釈文ファイルが出来上がる。

暦日データについても、理論的に正規化の問題が生じるが、暦日索引の編集においてはあまり深入りはしなかったので、今回のデータ加工に当たっても特別な対応は求められず、readdates, histdatetagging, histdatesreplacemntという三つのファンクションで、暦日データを読み込み、タグ付けした上で釈文ファイルに置換挿入することが簡単にできた。
上記の加工過程を通じて最終的にindexdata.pyによって出力されるタグ付けの釈文ファイル(shakumon(with tags).txt)は、釈文ファイルの予備的加工で紹介した釈文ファイルと同じ形式に整えられており、データも、索引収録の語彙を暫定的なタグで明示している以外、全く同じである。だから、釈文ファイルをhtmlファイルに変換するスクリプト(htmlcreator01.py)に、このタグに基づいて関連ファイルにリンクを貼るファンクションを追加さえすれば、3 HTML形式の資料庫構想で紹介したhtmlファイルの改良バージョンが出来上がる。本来はそうした機能を追加した「htmlcreator02.py」というスクリプトを書く予定であったが、後述のデータの不整合性問題から、今回はそれを断念することとなった。
問題点
我々が索引稿に託した情報は、正規化表記の中に分散してしまい、しかも不規則的な形をしているから、復原は実に大変であった。上記のフローチャートで言えば、stringorireplacement・stringprep・indexdataconsolidation・stringprepremoval・sliptextreplacementの諸ファンクションが行う作業は本来全く不要なものであり、tagprep・taggingが行った作業のみ最初から釈文データに対して実施すれば、事が済んだはずである。つまり、最初からタグ体系を作ってしまえば、索引編集のような苦労は一回で済み、それによって得られた情報は、機械処理にて、編集・改編等に何度でも繰り返し使える。
refstringの存在も手作業による索引編集の名残である。2 索引稿の編集のkanshokumeisakuin(kisodata).xlsxでは、複合的官職呼称等を、構成語の数だけ重複して収録し、並び順を徐々に変えて見出し語となる語を冒頭に配置するレコードを生成した。索引データの出力に当たっては、この配置に基づき、本項目と参照項目を識別し、各見出し語の下に配置した。つまり、索引データでは、この配置に、複合呼称の構成情報が含まれることになっている。そのため、indexdata.pyは、stringとrefstringのデータを交互に参照しつつ構成情報を復元せざるを得なかったが、それはもちろん情報学的には本末転倒である。本来は、タグで構成情報を正確に記述し、諸種の出力・表示の必要に応じて機械的に処理すべきものである。
索引データの解析によって得られた情報には数多くの不整合性が確認されてしまった。元の心づもりでは、shakumon(indexdata).txtは、手動で貼り付けたリンクより遥かに正確に索引データに含まれている語彙情報を反映するはずであった。しかし、蓋を開けてみると、得られた情報は、とても安心して使える代物ではなかった。2 索引稿の編集と3 HTML形式の資料庫構想との間でも、各索引の相互間においても、編集方針や語の捉え方は違ったりしているだけではなく、解析の過程において、手動で不整合性を訂正しようとしたら、間違いがむしろ増幅されることとなった。
幾つかの具体例を取り上げよう。一つには、前述したhtmlcreator02.pyを作成する準備作業として、索引データの解析によって得られた見出し語と、3 HTML形式の資料庫の語釈ファイルに用いられた見出し語を照合するmidashigoshogo.py(midashigoshogo.zip)というスクリプトを書いた。その結果、索引データの1300個弱の見出し語に対し、2-3百個の食い違いが生じた(midashigoshogo.zipの中の「out(sakuinketuraku).txt」と「out(goshakuketuraku).txt」を参照)。そうした状況から、自動的に索引データを反映した資料庫の「改良」バージョンを生成しても、ほとんど意味がないと判断せざるを得なかった。
同様な不整合性は、indexdata.pyから出力させた諸種のログファイルからも数多く読み取れる。語の捉え方とタグ付けに関わる例を二つだけ紹介し、本章を閉じてこうした問題が回避できると考えられるTEIエンコーディングの実験に移っていきたい。
索引間で編集方針が必ずしも一致していなかったため、一部語の捉え方が齟齬し、タグに不整合性が生じた。例えば、簡8-0706b+8-0704bには、「都郵人羽」と見える。「羽」は人名であり、この人は都郵にて郵人として仕事をしていたが、「都郵人羽」という文字列については、二つの点で意見が分かれていた。一つには、「郵人」が官職名か身分か、である。役務として住民に割り振られるから、「郵人」は身分の一種として身分呼称索引に加えるべしと考えられる一方、国家機構にて行政業務の一部に恒常的に携わるから、官職名索引から省くことも躊躇される。そのため、結局両索引に重複してこの文字列を収録することとなったが、indexdata.pyは、両索引に見える「郵人」という見出し語にそれぞれ「863」と「1006」という通し番号を附し、タグ付けにおいては便宜的に<1006>と<863>を<1006/863>に纏めておいた。こうした便法はもちろん厳格なXMLファイルには通用しまいが、情報量に変化がないから、タグ体系構築に当たり、簡単に対応できよう。
この文字列で困ったのはむしろ語の捉え方である。「羽」は「都郵」の「人」でもなければ、「都」の「郵人」でもない。それは、この用例および関連する同時代の資料においては「人」が独立した身分呼称としても官職名としても使われず、「都」も独立した「官署名」として見受けられないからである。とくに官署名をも収録する官職名索引において、これは問題となった。「都郵」と「郵人」という二つの語を見出し語に立てたため、両者には、それぞれ別の通し番号が割り振られた。indexdata.pyは、通し番号をタグ付けに用いるが、官職名索引に関わるタグ付けの結果は次の通りとなった。
<office><805>都<863>郵</805>人</863>羽</office>
「<office>」と「</office>」は文字列全体を官職名に関わるものとしてマークし、「<805>」「</805>」と「<863>」「</863>」はそれぞれ「都郵」と「郵人」とをマークする。「都郵」と「郵人」とでは、「郵」の一字が重なり合うから、タグ付けにおいてもタグ付けされた文字列が重なり合い、「<805>」と「</805>」の間に「<863>」が、「<863>」「</863>」の間に「</805>」のタグが混じれ込んでしまうこととなった。これはXMLで禁止される状況である。
しかも、これは、XMLに特有の問題ではない。言語学的にも、これは、「都郵人」をどのように解析すべきかと密接に関わっており、矛盾が生じたのは、この問いに正面から答えなかったからである。一つの可能な解釈としては、「都郵人」はあくまでも「都郵」の「郵人」を指しており、言語使用において「都郵人」に縮められたと考えられる。そうすると、正規化表記としては「都郵(郵)人」、タグ付けとしては「<805>都郵</805><863>(郵)人</863>」が有力な一案となろう。こうしてみると、XMLのタグ付けにおける厳格な形式的制限は、負担というよりも、むしろ言語学的な問題にぎっちりと道筋を付けるのに手助けとなるとも言えよう。
もう一つの例としては、空のタグを取り上げる。前述の「都郵(郵)人」でも類似した問題が発生することになるが、indexdata.pyの出力結果の実例から取り上げると、例えば簡8-0692aには、「庫嗇夫」を勤めている「建」という人物が見える。原文表記は「庫建」であり、shakumon(with tags).txtにおけるタグ付けは「<office><123>庫</123><456></456><persname><173>建</173></persname></office>」となっている。中では、「<456></456>」は正規化表記の「庫(嗇夫)建」において補った官職名の「嗇夫」に対応する。これは原文にはない付加情報であるので、原文の形を変えないように、indexdata.pyによる出力に先立ってそれをstringprepremovalを使って削除しておいた。「都郵(郵)人」でも、タグ付け後の釈文は実際には「<805>都郵</805><863>人</863>」となり、恰も「<863>」が「人」という語をマークするかの印象を与える。
これはもちろんindexdata.pyの便宜的なタグ付けによって生じた表示結果に過ぎない。その意味では、それは、必ずしも大きな情報学的矛盾ではない。出力に当たって適当な表示形式を選べばよいだけの話である。同時に、それは今後のタグ体系の構築に関して警鐘を鳴らす現象である。構築に当たり、原文にない付加情報をどのように表現すべきかという問題に、真剣に取り組まなければならない必要性を示すからである。
参考文献
5 形態と様式分類のデータ収集(2023年5月1日~2023年8月30日作成、2024年7月23日公開、2024年8月2日リンク訂正)
文書簡牘の古文書学的研究は、文字記載のみを対象とする学問ではない。如何なる形態の簡牘に、文字がどのように配置されているかという問いは、文書の作成から移動・保管・再利用を経て廃棄に至るまでの「ライフサイクル」を明らかにするうえで、記載内容に劣らない重要性を持つ。『里耶秦簡(壹)』収録の簡牘を主要対象としていた1 ワード形式の訳注稿は、すでに様式分類に従った配置原理を最大の特徴としていたが、2023年度の前半には、鈴木直美氏が取り纏め責任者を務め、『里耶秦簡(貮)』収録の簡牘を対象に、メンバーの共同作業で組織的に関連データを収集したので、以下その概要を示す。……展開する/折りたたむ
特徴
我々が用いる形体と様式の分類は、髙村武幸氏が西北漢簡に基づいて開発した中国古代簡牘分類に負うところが大きいが、幾つかの変更点がある。
形態分類については、髙村分類が全ての簡牘に対して一つの分類記号を与えて簡牘の集成に寄与するものであるのに対し、我々は形態分類をデータの定型化と収集に役立てようと考える。例えば、髙村分類は、簡牘の形態を大きく側面加工のないもの(〇型)や左右の側面に対称的加工を施したもの(一型)等、都合五つの部類に分け、その下でさらに例えば〇型の簡牘をその幅や書写された行数等を基準に、また一型の簡牘を側面加工の様態を基準に細分化する。それで、簡牘を最も基本的な形態特徴に基づいて分類して集成することが可能となり、更なる考察に利便性を与えることになるが、例えば一型等に関しては、〇型の細分化基準となる幅や書写行数等に関わる情報は、失われることになる。諸種の表面加工に関わる情報も、基本形態の分類の下位分類に位置づけられるため、全ての簡牘について系統的に収集することは困難になる、そこで、できるだけ多くの形態情報を集めようとする我々の研究関心から、書写面の取り方や表面の加工は、簡牘の基本形態から独立させ、それぞれ別途に情報を収集した。
残欠情報や再利用状況に関しても、髙村分類では簡を単位に、形態分類が正確に行えないほどの残欠が観察される簡牘を残欠簡に、再利用による変造が明らかな簡牘を再利用簡に分類していたが、前述の方針にしたがい、全ての簡牘について関連情報を形態情報と重ねて収集する方針を立てた。
各分類は次の通りとした。
|
基本形態 |
|
|
〇型:短冊形 |
|
|
一型:左右対称加工 |
|
|
二型:左右非対称加工 |
|
|
三型:多面体・封泥匣なし |
|
|
四型:封泥匣あり |
(一型~四型の側面・立体加工による細分類は髙村分類に従う。) |
|
書写面の形態 |
|
|
書一:一行書き |
|
|
書二甲:二行書き平坦 |
|
|
書二乙:二行書き稜線 |
|
|
書三甲:三行以上平坦 |
|
|
書三乙:三行以上稜線 |
|
|
書四:横長 |
|
|
書五:無文字 |
|
|
表面加工の形態 |
|
|
表一:墨・朱塗 |
|
|
表一甲:網掛模様 |
|
|
表一乙:塗りつぶし |
|
|
表一丙:墨点 |
|
|
表二:罫線 |
|
|
表二甲:墨 |
|
|
表二乙:朱 |
|
|
表二丙:刻 |
|
|
他の特殊加工形態 |
|
|
特一:孔 |
|
|
特二:切断用の切り込み |
|
|
残欠状況 |
|
|
残(縦) |
|
|
完 |
|
|
上残 |
|
|
下残 |
|
|
上下残 |
|
|
残(横) |
|
|
完 |
|
|
左残 |
|
|
右残 |
|
|
左右残 |
そのほか、比較的不規則的な部分的欠損は「上缺右角」等の例示をしつつ、自由記述に委ねた。 |
なお、髙村武幸氏の簡牘分類については、同氏「中国古代簡牘分類試論」(木簡研究第34号、2012。又、同氏『秦漢簡牘史料研究』付篇第三章「中国古代簡牘の分類について」(汲古書院、2015年))を参照されたい。
得られた形態・様式データは、keitaiyoshikidata.xlsxからご覧いただけます。
問題点
今回のデータ収集は、単独観察者による図版上の比較的簡易な予備観察に基づく。このデータは、共同史料講読に際し、共同討議に付され、より詳しい図版上の観察のたたき台として利用する予定である。共同観察の結果疑問の残る簡については、将来現地調査を行う必要がある。
様式分類に関しては、依然として簿籍の分類は訳注稿の暫定的な方法によっており、1 ワード形式の訳注稿ですでに述べた問題点をそのまま含んでいる。引き続き簿籍分類の根本的改変を進めなければならない。
また、簡・簡面・文書という三つの情報単位がまだ正確に区別されていない点も、訳注稿と変わりがない。今後DBに組み込むためにCSVファイルに作り替える際、根本的な解決を図らなければならない。
最後に、簡牘の再利用に関しては、今回のような比較的簡易な予備的観察では、信頼に堪える情報が得られる見込みがないので、今回のデータ収集からそれを省いておいた。
4 DB構想(2024年7月10日公開)
3 HTML形式の資料庫構想の問題点の根本的な解決には、情報の記述・管理と情報の表示が峻別できる総合的なデータベース(DB)の構築が望まれるが、簡牘に適合的なDBを設計するに当たり、何よりも構造化情報と非構造化情報が混在するという現状を直視することが不可欠だと考える。構造化情報とは、やや単純化して言えば、エクセルのような表計算ソフトに簡単に一覧できるようなデータをいう。コンマで区切られたCSVという特殊なテキストファイルで保存することが多いが、実質は同じである。予めデータの構造が判明し、全てのレコード(エクセルの行)を通じて、一定数のフィールド(エクセルの列)に情報が収まる。非構造化情報は、生きた言葉のように、ぎっちりと構成原理が決まっておらず、表形式に纏めようとしても、常に処理しきれない残余がでてきたり、用意したフィールドが合わなかったりする。文書簡牘の場合には、とくに記載テキストにそうした情報が集中的に現れる。……展開する/折りたたむ
構造化情報を備蓄・管理するにはリレーショナルデータベース(RD)が最も効率がよいのに対し、非構造化情報たるテキストの機械処理には、テキストエンコーディングが大きな力を発揮すると考えられる。そうした発想の下で、次のようなDB構想を練ってみた。

特徴
RDの中心には、TEIに準拠してエンコードされたテキスト(≈釈文)が置かれる。テキストにおける特定様式・語彙等の出現はRDでいう「出来事」と捉え、この出来事を結節点として諸種の構造化データとの関連付けを行う。関連付けに必要なIDは、エンコーディング・タグの属性に含める。
TEI(Text Encoding Initiative)とは、テキストエンコーディングの国際標準化を目指して設立された国際コンソーシアムの名であり、またこのコンソーシアムが1990年以降複数のバージョンを発表してきたガイドラインの名でもある。国際標準化とはいうものの、テキストには無限の多様性があり、テキストごとにエンコーディングの調整が必要になる。TEIの一つの長所には、XML採用によって十全に保証できるようになった拡張性があり、テキストエンコーディングの命であるマークアップ体系を、異なるテキストの種類に合わせて変更することが可能である点が重要な特徴である。
我々が文書簡牘のテキストにおいてマークアップしたい情報は基本的に、釈文の釈読に関わる校訂情報・文書の様式論的特徴・文章を構成する語彙という三種類に分かれる。この三者の間では、最も適合と判断されるマークアップ体系に、テキスト指向型とドキュメント指向型の違いがあるほか、マークアップ対象となる文字列が複雑に重なり合うため、一つのXMLファイルにそれを同居させることは困難である。そのため、情報の三つの種類に適したマークアップ体系をそれぞれ別途に構築する予定である。
構造化情報は、テキストとは別にCSVに蓄積していく。そのIDをマークアップの属性に含めることにより、このデータをテキストデータと連結するが、3 HTML形式の資料庫構想でもみたように、こうしたデータが対応する情報の単位はそれぞれ異なる。出土地もしくは出土位置や法量等が簡を単位とするのに対し、様式は文書の単位、語彙はテキストのあちらこちらに散りばめられた字や語の単位で捉えて、テキストにおいてマークする必要がある。こうした情報の蓄積は、訳注や辞書の編集にも繋がる。
問題点
我々は情報学の専門家ではない。技術的なことを専門家に丸投げすれば、我々の自主性を失うことになり兼ねず、かといって会のメンバーが全てRDの運用に必要な知識を身につけることも必ずしも期待できない。自ら技術を勉強しつつ、不慣れな人も置いて行かれないように、配慮が不可欠である。
また、我々人文研究者が長年紙媒体の平面で文字資料を見てきた「慣れ」も見落としてはいけない。その感覚に最も近いのは実は情報の表示と記述を混淆した3でみてきたHTML形式の資料庫である。インターネットを閲覧するような感覚でDBの中身が自由に探求できたら、日頃の参照に最も便利であろう。
そして、HTML形式で閲覧したデータをどのように修正できるかが問われる。メンバーの修正意見をDBの管理言語に逐一翻訳する専業の世話役を雇う資金力もないので、ここもまた技術知識のギャップが大きな障害になりかねない。一つの解決方法は、フリーのリネーム・ソフトによくみられるように、定型化したテキストファイルのデータシートを書き換えることを通じて、修正に関わる指示をDBに伝達する方法が考えられる。データシートは、提出前に印刷することができるから、紙媒体への慣れに配慮できるのみならず、定型化が機械可読性を保証するから、自動的に全ての変更を記録するログファイルができよう。
そうしたことを、手持ち資料の持ち寄りから成果物の出力まで含めてフローチャートにしてみると、次のようなイメージ図ができあがる。
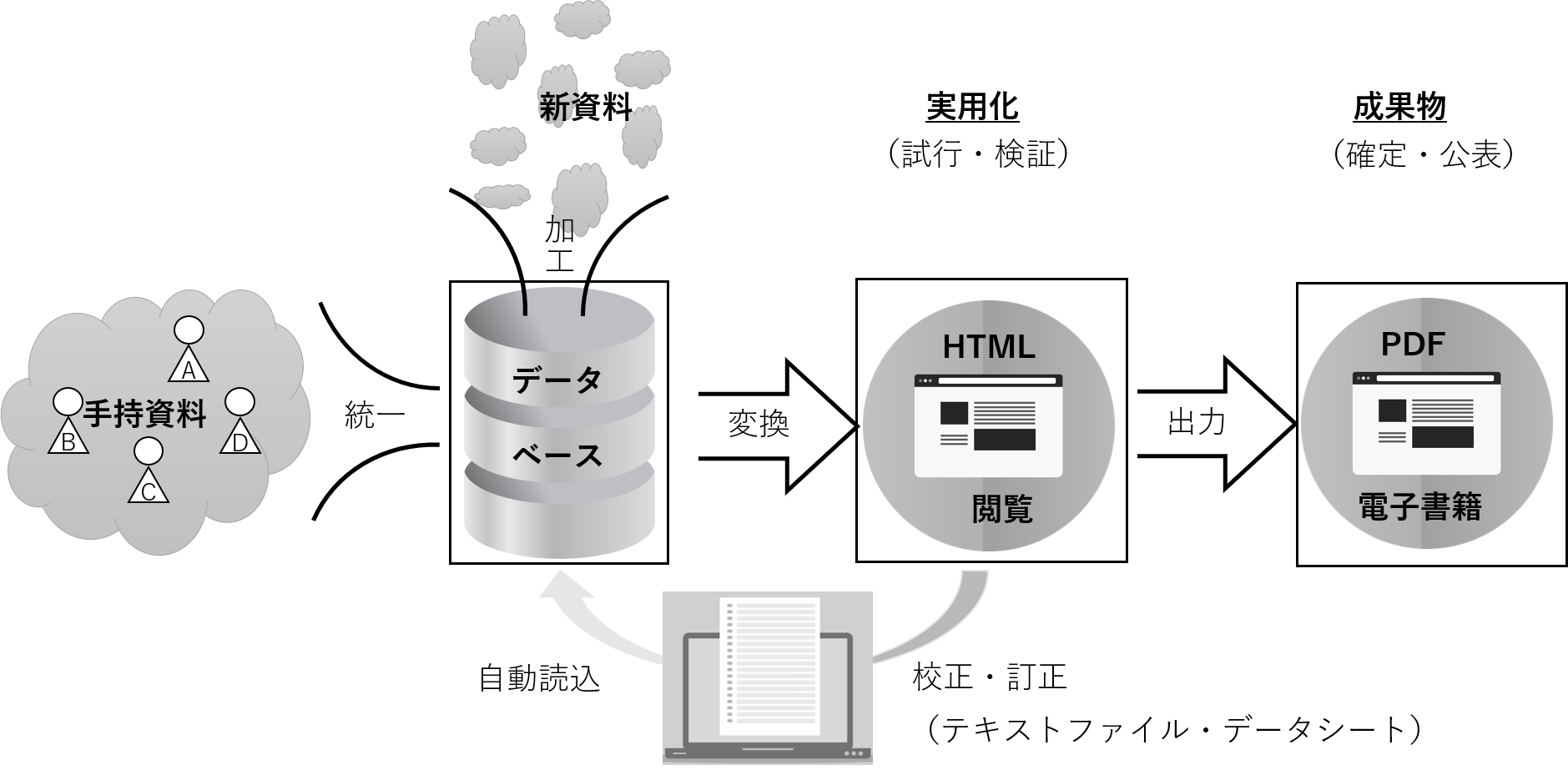
3 HTML形式の資料庫構想では、そうしたことを全部一つの工程で解決しようとしたから、無理が生じたが、機械的にデータが処理できるDBなら、それをHTML形式などで出力することは瞬時にできるはずである。故に、何よりもデータの機械可読性を如何に獲得できるかが喫緊の課題である。そのために、引き続きいろいろな実験を行う予定である。
3 HTML形式の資料庫構想(2022年7月31日作成、2024年6月30日公開)
簡牘学でも大量のデータを取り扱わなくなってしまったので、大量の基礎情報処理を人文学者が如何に自前で行えるかが問われる。市販ソフトや委託製作等に頼っていては、その仕様に研究が縛られ、また自らの手でリレーショナルデータベース(RDB)を設計するのも至難の業である。そこで、インターネット自体が大きなデータベースにほかならないから、その主要ファイル形式のHTMLこそ、我々の研究仲間がデータを蓄積して共有する最も手っ取り早い方法ではないか、という発想の下で、後述のワード形式の訳注稿をHTML形式の資料庫に作り替えてみた。さらに、飯田祥子氏がもっていた五一広場後漢簡牘のデータからも同様な資料庫を作製してみた。作業は2022年2月~7月までの間に行われ、陶安が技術開発を担当し、研究協力者として青木俊介・飯田祥子・石原遼平・鷲尾祐子の四氏が実際のデータ加工に当たった。……展開する/折りたたむ
特徴
HTMLは、原理的には、コーパスの如くテキスト性を失わずに文字データに関連情報を付与し、機械可読性を持たせるマークアップ言語である。その上、リンクを貼ることで多くのファイルを関連付けることも容易である。さらに、ブラウザにおいて表示結果を確認しつつ、テキストエディタのフォルダ内検索を通じて管理ができる。正規表現と簡単なPerlスクリプトさえ覚えれば、一般の文系出身の研究者でも、ファイル・フォルダ・リンクの自動生成から、語の自動識別や語彙分析等、資料性の強い電子書籍への出力を念頭に置いた総合的なデータ管理が可能になると考えた。
里耶秦簡を例に実際の構造について説明すると、資料庫は、簡牘の釈文を中核としており、釈文からハイパーリンクを伝って各種情報にアクセスできるように設計されている。
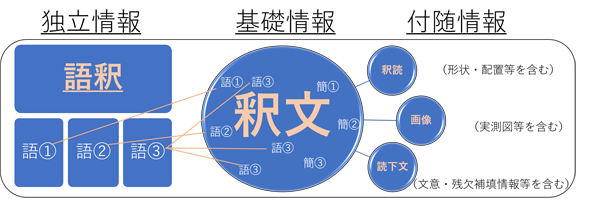
釈文は、1 ワード形式の訳注稿と同様に、原則的に「簡」を単位に、その簡に記された文書の様式論的特徴に従って配置されている。釈文はいわば資料庫の基礎情報であり、その配置には様式分類に関わる情報が内蔵されている。
釈文の周辺には、同じく簡を単位とした諸種の情報が付随する。例えば、その簡の釈読に関わる情報、釈文に対する日本語の読み下し文、簡牘の形態情報などがある。これらの情報は付随情報と考える。
付随情報を格納するためには、Perlスクリプトで簡番号をファイル名とするファイルを生成し、「Liya-shakudoku」および「Liya-yomikudashi」というフォルダーに収めた。釈文ファイルにおけるリンクもPerlスクリプトで最初から自動的に生成した。
簡とは異なる単位を持つ情報は、独立情報と位置付ける。資料庫試作品を作成した時は、それは主として索引稿に収録していた単語を単位とした官職名や身分呼称にかかわる文字列である。索引稿の見出し語一覧に基づいてPerlスクリプトで各ファイルを生成し、「Goshaku」というフォルダーに収めた。釈文ファイルにおけるリンクも試験的にPerlスクリプトで貼ってみた。
付随情報および独立情報自体は研究協力者が手動でワード形式の訳注稿からそれらのファイルに貼り付けた。作業の様相はsagyotejun.docxからご参照ください。独立情報へのリンクも手動で訂正した。Perlスクリプトは、見出し語と一致する文字列を検出する単純なものであるから、誤認識が多数あった。
釈文ファイルには図版へのリンクも貼っておいた。里耶秦簡の研究者は通常各自で研究用に公開の図版データを簡単位に加工しているが、それをjpg形式で「Liya-zuhan」というフォルダーに纏めて釈文ファイルと同じフォルダーに収めれば、釈文ファイルから図版も効率的に参照できる。(中国でも漸くIIIFによる画像データの公開が始まっており、その動きが簡牘所蔵機関に浸透した暁には、各個人が重複して図版を用意する手間が省けることになると期待したい。)
資料庫のイメージは次の図の通りである。
実際に作成した資料庫試作品はLiya-shakumon.htmlから開ける。多くの語釈ファイル等が未記入のままとなったり、画像ファイルを利用者個人に用意していただかないとリンク切れとなったりし、決して理想的な形にはなっていないが、リンクを伝って暦日・語釈や釈読・読み下し等、異なる情報類型間を自由に行き来し効率的に参照できる感覚は十分に味わっていただけるかと思う。
同じような付随情報を伴った釈文を、複数の資料群を対象に作り、次の図のように、総合的な資料庫を構築していく、というのが元の計画であった。
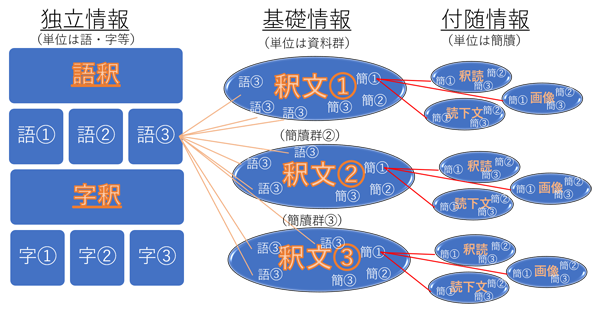
この計画を後述の技術的な問題で中止する前には、里耶秦簡のほかに五一広場後漢簡牘の試作品のみが完成した。これは、飯田祥子氏がもっていたデータを基に作成したものである。飯田氏が五一広場後漢簡牘に対する考察を基に考案した様式分類に従って釈文が配置されている点と、正確な法量データが附せられている点が最大の特徴である。読み下し文はまだ付けられておらず、また里耶秦簡と同様に現時点では利用者ご自身に画像ファイルを用意していただかなければ、機械的に貼ったリンクは、リンク切れとなる。釈文ファイルはここから開ける。
問題点
最大の問題点は、情報の保管と表示を混同してしまっている点である。
元の計画では、HTMLファイルのリンクおよびその参照先のフォルダーやファイル構造に情報が蓄積されると考えた。確かに、里耶秦簡には、例えば「蜀」という語は、官署名もしくは地名である郡名のほか人名としても出現し、字面では両者に明確な差異がないが、リンクはマーカーの役割を果たし、HTML形式の釈文ファイルでは両者は明確に区別されている。どちらか一つのみ集めようと思えば、それは実に簡単にできる。
しかし、HTMLファイルは明らかに表示機能に最適化されている。それ故に、リンク等に書き込んだ情報の訂正や追加などのメンテナンス作業は極めて煩雑で不正確になる。やはり情報の蓄積・保管と表示・利用とを明確に区別する必要がある。
また、釈文は、「簡」を単位にと考えていたが、実際はワード形式の訳注稿には「簡牘」・「簡面」および複数の簡面にわたる「文書」を最小単位とする場合が混在していたのをそのまま継承してしまった。特に、複数の簡面にわたる「文書」を単位とした場合には、自動生成したファイル名と齟齬が生じ、リンク切れを引き起こす原因となった。試作品では、作業協力者に手動でファイル名を訂正していただいたが、やはり情報の単位をより厳密に定義し、明確に使い分けなければならない。
補足説明
Perlスクリプトによる自動リンク貼りは、提案型ツールの簡単な手本にもなり得るので、仕組みの説明と共にそのスクリプトを掲げておく。
linkcreator.plは、Liya-shakumon(linknuki).htmlに対し、linkkomoku.txtというリンク貼り項目の一覧に基づいて語釈に関わるリンクを貼り、Liya-shakumon(linkari).htmlとして出力する。一覧の項目を釈文ファイルから検出し機械的にリンクを含んだ文字列に置き換えるから、誤認識も多いが、それを校正する形で語彙情報が蓄積できるから、幾らか手作業が省けると言える。
なお、Liya-shakumon(linknuki).htmlとは、例示のため、上記の釈文ファイルから語釈に関わるリンクをlinkdeleter01.plで削除したファイルである。第34行冒頭の「#」を削除して実行すると、暦日のリンクも削除される。linkkomoku.txtは、手動で索引見出し語の中から選んだ項目の一覧であるが、見出し語の選択およびリンク情報の生成には、語釈ファイルのファイル名管理にも使ったgoshakufilekanri.xlsxというエクセルファイルを借用し、項目を長い順に並べ直した。誤認識の特に高い一文字だけの見出し語は、人名にしか使われないことが分かる特殊な場合にのみ項目一覧に含めた。(goshakufilekanri.xlsxには、仮名をヘボン式ローマ字に変換するアドインが必要になるが、https://www.vector.co.jp/soft/data/business/se493167.htmlから無料でダウンロードできる。
また、外字については、画像に置き換えて釈文ファイルに組み込んだ。外字の管理のためには、「Gaiji」というフォルダーに画像データを纏め、且つgaijiichiran.docxに字形が判る一覧表を設けた。里耶秦簡は秦系文字に係るため、外字の数は必ずしも多くなく、楚簡や金文などと比べると、それほど大きな問題とはならなかった。
上記の問題点に拘らず、資料庫の試作品は、幾らか参照の利便性を提供し、読者の方にご利用いただく価値はあるように思われる。里耶秦簡の資料庫の中身は、基本的に、1 ワード形式の訳注稿と変わらず、内容的に多くの問題点を残しており、また五一広場後漢簡牘の試作品も、データ提供者の飯田氏の現時点での理解を正確に反映してはいないが、この点にさえご留意いただければ、次のzip.fileをダウンロードの上日頃の参照のためにご使用いただくことに差し支えない。Zipファイルを解凍し、生成されたフォルダの中でLiya-shakumon.htmlもしくはGoichi-shakumon.htmlを開いていただければ、そのファイルから各種情報にアクセスできる。引用していただく際は、出典を次のように表記していただければ幸いである。
補記(2024年7月6日)
里耶秦簡の場合は、手探りでデータ加工を進め、しかも手作業と機械処理とが交互に入れ混じっていたので、今となっては、加工工程の再現も、正確なドキュメンテーションも、もはや不可能に等しい。それに対し、五一広場後漢簡牘の資料庫は、里耶秦簡の経験を振り返りつつ、飯田氏が纏めたデータから一気に生成した。エクセルファイルからデータをよりアクセスしやすいテキストファイルに移し替える作業を除けば、全ての処理をPerlスクリプトで行ったので、全く同じ作業を正確に再現することは今でも可能である。
さらに、研究仲間に機械処理を理解してもらうためにも、それなりの工夫をしてみた。一つには、全工程を無数の小さなプロセスに区切り、プロセスごとにその操作が体験できるように独立したスクリプトを用意した。また、各プロセスについて詳しく説明した「釈文生成指南.txt」を作成してみた。それは今、詳細なドキュメンテーションとしても、初心者のチュートリアルとしても利用できる。
ご関心のある方はどうぞHTML-DB-tools.zipからダウンロードしてください。都合64のファイルが収められているが、「Goichi-DB220727.xlsx」には飯田氏が用意していた元のデータが格納されており、そこから各スクリプトを使って、五一広場後漢簡牘の資料庫試作品を構成する「Goichi-shakumon.html」「Goichi-horyoichiran.html」および各簡に関わる411の釈読情報ファイルを収めた「Goichi-shakudoku」のフォルダを機械的に生成することができる。詳細を記した「釈文生成指南.txt」は、章節の標題の冒頭に半角の「.」を置いたので、アウトラインバーのプロパティを、「.」を拾うように設定していただくと、より参照しやすくなる。
なお、補記を準備する過程では、2024年6月30日に公開した五一広場後漢簡牘の資料庫試作品が2022年7月末日の最新バージョンではなく、製作途中の別バージョンであったことに気付いた。そのため、各ファイルを7月末日のバージョンと差し替えたので、ここに記しておく。
2 索引稿の編集(2021年11月30日索引稿公刊、2024年6月30日説明公開)
索引の編集自体はまだ手動で後掲の訳注稿から項目を拾っていくアナログ方式で行ったが、千以上のリンクを伝って内部を自由に行き来できる電子書籍として索引稿が完成すると、電子書籍が秘める可能性に魅了されてしまった。電子書籍はただ単に紙媒体の平面を電子的に再現したものではない。東京外国語大学学術成果コレクションからダウンロードできるので、是非お試しいただきたい。
しかし、従来の手作業では、電子書籍の可能性を十全に発揮できるだけのデータを効率的に集めることは甚だ困難である、ということも、この編集作業によって明らかになった。これは3 HTML形式の資料庫構想を練り始めるきっかけと動機となったが、以下はまず索引稿の編集における情報の(やや不手際な)扱い方について紹介しておきたい。。……展開する/折りたたむ
特徴
秦国は、人々の労働を財政の重要な柱と位置付けた。全国の隅々まで住民を効率よく使役するためにこの国家は綿密な個人情報の収集と管理を行っていた。本索引は、何よりも官府が管理していたそうした情報の復原に努めた。
個人情報は、人名・地名・爵位・役職等、多数の要素から構成されている。一つ一つの要素は、それぞれ一語と捉え、語と出現箇所の一覧表としてそれを通常通りの索引に纏めることができようが、本索引では諸要素の組み合わせを可視化することに強く意を用いた。そのため、官職名索引と身分呼称索引では、下図のように複数の要素からなる複合的官職名や身分呼称を、一つの有意義な纏まりと捉えつつ、各要素からも参照できるように、対応する複数の見出し語の下に重ねて収録した。
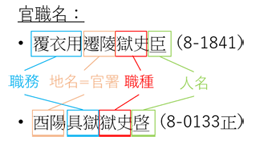
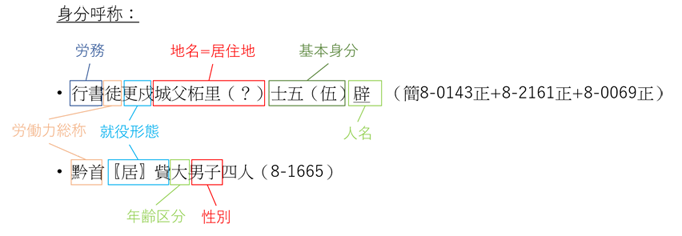
原文における表記の揺れにも一定の配慮をしてみた。貮春郷という行政単位を貮郷と称することもあれば、沅陵という県名の用字を元陵に改める場合もある。そのほかに、庫や倉等は、単独では官署を指すのに対し、人名の前に置かれる場合にはその長官である庫嗇夫や倉嗇夫を指す官職名に転用される。そうした関連性や違いを明示するために、各語の意味を正確に表現する正規化表記を工夫し、原文と併記して掲げることとした。(索引データの構造については、さらに6 索引データの再分析においてより詳しく説明する予定であるので、今後それもご参照ください。
そして、複合的な呼称の構成原理および正規化の規則を明確にするためには、官職名索引と身分呼称索引の前にさらに「官職名総覧」(『里耶秦簡索引稿(壹)』80-90頁))と「身分呼称総覧」(同235-260頁))を附し、索引本文の各見出し語との間にリンクを貼った。
時間も、国家による社会統制の重要な要素であるから、索引稿には暦日索引も設けた。暦日索引は、簡番号順と暦日順と、二つの並べ替え原理に従って配置した部に分かれる。暦日順のデータは例えば今後『里耶秦簡編年』を編集する場合に役立つであろう。或いは個別的に官吏の履歴を調べる際にも同様な資料の並びが有意義ではないかと思う。
なお、ヨーロッパやアメリカでは、暦日と言えば、西暦のグレゴリオ暦とかユリウス暦への換算に関心が向けられるが、秦漢時代には、日もしくは月の時間単位が気になるほど、地中海世界や西アジア等との間の交流は頻繁ではなかったので、日本や中国の古代史研究者の間ではあまり関心が示されないように思われる。天文学的現象の比定等が問われる先秦時代の通時代的年代学的研究ならともかく、里耶秦簡の前述した編年といった研究関心からするならば、始皇帝と二世の治世について秦暦における暦日の相対的な位置を見極めれば十分である。そのために、暦日は、張培瑜「根據新出曆日簡牘試論秦和漢初的曆法」(中原文物、2007年第5期)を参照することにとどめた。
問題点
索引項目の収集にはエクセルファイルを用いた。官職名索引を例に説明すると、最初は基礎データをkanshokumeisakuin(kisodata).xlsxに集め、それからkanshokumeisakuin(narabekae).xlsxでそれを並べ替えて索引の原稿として出力できる体裁に整えた。後者の方を開いていただくと、通常のスペックでは相当時間が掛かるに違いない。ワード形式と同様に、パソコンに過剰な負荷を掛けることやクラウド上の共同作業に向かないことはすぐに実感していただけるかと思う。
より原理的な問題としては、複合呼称の纏まりを温存しつつ、構成要素を区別して「単語」としてエクセルに認識させるには、下図の「洞庭假卒史悍」のように、構成要素の順番を入れ替えつつ複合呼称を重複して収録する必要が生じてしまった。或いは我々の限られた情報学的知識では、それ以上スマートな方法が思い浮かべなかっただけなのかもしれない。それはともかく、本来一つのデータに過ぎないのに、索引における並べ替えや表示の都合で重複して収録することは、余計な誤字・脱字の原因となるので、情報学的禁じ手というべきに違いない。
.JPG)
その上に、人名を人名として認識させるには、「_悍」のように、アンダースコアを置いたり、「主(脇付)」と「主(動詞)」のような同形の語等を区別するために「[]」や「()」等の括弧で囲った付加情報を挿入したりしたので、手作業を誤らせる誘因を量産してしまった。実際に手作業を担当した仲間がよくそれに耐えたものと振返って思う次第である。
補足説明
並べ替え用のファイルの仕組みをもう少し説明すると、kanshokumeisakuin(kisodata).xlsxには、対象となる文字列を単語に区切って収録しているが、そのデータは、kanshokumeisakuin(narabekae).xlsxでも、「基礎データ」シートとして用いられる。「見出し語抽出」シートの「見出し語抽出」テーブルはまずそこから全ての語を読み取り一覧しておく。UNIQUE関数で重複を削除してから見出し語を「見出番号」テーブルに移し替え、「字音画数表」シートを参照しつつ漢音の五十音および画数に従って、序数を附していく。UNIQUE関数の結果をテーブルに取り込むのが技術的に難しいので、この移し替えは、手動で行なった。「見出番号」テーブルにおいて生成された序数は自動的に、「見出し語抽出」テーブルの見出番号欄に反映される。「並べ替え用」シートは、「基礎データ」テーブルから文字列と、「見出し語抽出」テーブルから見出し語および見出番号を取得して、不要な括弧(「()」や「[]」)を削除した上で、また「字音画数表」シートを参照して全体の並べ替えを行う。最後に、「出力用」シートは、頭文字や見出し語を適宜挿入しつつ、正しい順番に文字列の正規化表記と原文および簡番号を一覧してくれる。右側四列(見出し語(調整)・正規化表記・簡番号・原文)のデータをコピーしてテキストファイルに貼り付けることで、入稿できる原稿が完成する。
原稿完成後誤字や並べ替えミスなどが発覚すると、原稿を手動で修正せず、基礎データや字音画数表を訂正してから、並べ替えやテキストファイルへの貼り付けの作業を繰り返す。(なお、入稿後は、通常の校正ゲラーによる校正を行ったので、公刊の『里耶秦簡(壹)索引稿』と完全に一致するデータのエクセルファイルは残念ながら残せなかった。)
字音画数表は、正字の漢音に従って色々な文字列を並べ替えるにも応用できるので、jionkakusuhyo.xlsxという単独ファイルにも入れておいた。「並べ替え用」シートの「文字列」に並べ替えたい文字列を貼り付けていただくと、テーブルが自動的に拡張され、「C1」から「C5」までの列に対応する序数が表示されるはずである。右の「C5」から左に向かって順に「C1」まで昇順に並べ替えると、正確に最初の五文字の字音と画数に従った配列となる。(なお、エクセルの設定により自動的に拡張されない場合もある。)
索引稿は旧字を用いたが、日頃の管理と検索には新字を使った方が便利である。新旧の対照表もjionkakusuhyo.xlsxに付した。replace.plというPerlスクリプトは機械的に置き換えられる文字を新字から旧字に置き換える仕事をしてくれる。新旧字の置換をしてくれるワード等ののプラグインも複数存在するが、缺と欠、絲と糸、餘と余など、新字が別字で旧字を代用する場合にも機械的に置き換えてしまうから、印刷原稿には使いにくい面がある。jionkakusuhyo.xlsxの新旧対照表では、諸種の俗字や異体字等と共にそうした個別判断を必要とする字を省いたので、残りの字はreplace.plで安心して置き換えられる。
実際に使っていただくには、Perlをインストールしていただくほか、replace.plをokikaekomoku.txtおよび置換対象のテキストファイルと同じフォルダーに置いていただく必要がある。okikaekomoku.txtはjionkakusuhyo.xlsxの「新旧対照表」シートの「新旧対照表_日本語」テーブルの「舊」と「新」の二つの列を貼り付けたテキストファイルである。旧字から新字に置き換えたい場合は、二つの列を入れ替えてからreplace.plを実行してください。置き換えたいテキストは「in.txt」というテキストファイルに格納する必要がある。置き換え後のテキストは「out.txt」に、置き換えた文字の一覧は「log.txt」に出力されるので、同名のファイルがあれば、実行前に別のフォルダーに移し替える必要がある。上書きされてデータが失われるからである。
なお、漢音の確認には、紙媒体の角川漢和中辞典とデジタルの新漢語林第二版のほか、陳彭年《宋本廣韻・永祿本韻鏡》(江蘇教育出版社、2002)を用いた。jionkakusuhyo.xlsxは索引稿編集で対象とした『里耶秦簡(壹)』にたまたま出現した文字しか収録していないので、お使いの際は、適宜必要な字を補記してください。補記に当たって、テキストに出現する文字を機械的に一覧する必要がある場合、characterlist.plが便利かもしれない。テキストを「in.txt」に格納して実行すると、文字の一覧が「Mojiichiran.txt」として出力される。ここも、上書きされてしまうので、同名のファイルを同じフォルダーに置かないでください。
最後に、暦日データを管理するエクセルファイルを説明しよう。rekijitusakuin01.xlsxは、暦日の換算と並べ替えに用いたエクセルファイルである。黄色の色掛けがある「基礎データ」シートの「簡番号」と「標準暦日」の欄は、基礎データを入力するフィールドであり、索引収録の全てのデータが収められている。都合878個の暦日である。簡番号は正背を「正」と「背」で表現する形式であるが、「番号順並べ替え」の欄では、「正」「背」「側は「a」「b」「c」に置き換えられる。この欄は番号順に並べ替えるために用いられる。「標準暦日」とは、暦日の正規化した表記であり、推測しうる欠損部分や省略部分は「【卅三年十二】」や「(廿九年)」等のように補われている。欠損部分が判らない場合は「【…】」と表記される。また、「二十」「三十」の漢数字は原文表記の「廿」と「卅」に従った。
「換算表」シートでは、「暦日加工」欄は、暦日解析の邪魔となる括弧を削除した上で「標準暦日」のデータを読み込む。「年(漢字)」「年(行)」「月(漢字)」「月(列)」「朔日(漢字)」「朔日(序数)」「干支」「干支(序数)」「日(参照)」の諸欄は「暦日加工」から年月日を読み取る。「行」と「列」は年月の漢字表記を、「朔閏表」シートにおける年と月の位置を示す数字に置き換える。「日(参照)」は、秦王政元年から秦二世三年十二月までの暦日の全ての暦日を一覧にした「暦日総覧」シートの「総覧_値」テーブルを参照して日付を返す。「朔日(算出)」「朔日(序数)2」「朔日チェック」「朔日(確認)」「干支(算出)」「干支(確認)」の各欄は、「朔閏表」に基づいて日を計算し、「総覧_値」テーブルを参照して得られた日付と比較してチェックを行う。
「年(数字)」「月(数字)」「日(数字)」は、年月日を並べ替えやすい数字に置き換える。秦王政元年から秦始皇三十七年には、101から137までの数字を割り当てる。上一桁の「1」は嬴政時代の暦日であることを示す。秦二世の暦日は、上一桁の「2」と下二桁の「01」もしくは「02」で表す。年が全く判読できない場合は「999」、上一桁のみ分かる場合(「十/廿/卅□年」)は、「191/192/193」、下一桁のみの場合(「□二年」「□五年」等)は、「992」「995」等を割り当てる。月については、年度が十月から始まるから、十月から十二月までは「010」~「012」とし、正月(端月)から「101」「102」等と数え、年末に置かれる閏九月を「119」とする。月が判読できない場合は「999」と、「十□月」は「019」で表す。日については、完全に判る場合と全く分からない場合に二分されるが、前者は二桁の序数をそのまま使用し、後者は「99」とする。以上の規則により、全ての暦日が正確に年代順に並べ替えられる八桁の数字が得られる。「基礎データ」シートの「時系列並べ替え」欄は「年(数字)」「月(数字)」「日(数字)」からこの数字を読み取って結合し、基礎データの並べ替えに供する(不明なデータは末尾に付せられる)。
このファイルには、現在『里耶秦簡(壹)索引稿』所収の暦日が格納されているが、「標準暦日」欄の末尾に新しい暦日を、正規化した表記で追記していけば、自動的にその年月日が算出される。「標準暦日」欄のデータを全て削除してゼロからデータ蓄積を始めるのも差し支えない。或いは「朔閏表」等を書き換えていけば、ほかの時代の暦日にも本ファイルを適用することが可能になる。その場合には、年だけでも西暦に換算した方がよいので、「基礎データ」シートと「換算表」シートに必要フィールドを追加したファイルとしてrekijitusakuin02.xlsxを用意してみた。
1 ワード形式の訳注稿(2014年4月1日~2022年1月31日作成、2024年6月30日公開)
これは最も伝統的なやり方である。陶安が音頭をとり、それまでの共同講読の結果をワード形式の訳注原稿に纏め、その後講読の度ごとに修正を加えて新しい知見を蓄積していった。里耶秦簡が1万枚以上ではなく約1千枚なら、それで通常の書籍として疾うに世に問えたところであろう。……展開する/折りたたむ
特徴
訳注稿の最大の特徴は、全ての史料を、その史料自体に基づいて構築した様式論体系に則して分類して配列している点にある。文書や帳簿などが一定の様式に基づいて作成されている以上、様式の把握は、簡牘の作成から保管・再利用を経て廃棄に至るまでのライフサイクルを明らかにすることを可能にする。それは、また簡牘に記された文書・帳簿を通じて、当時の官府が如何に住民などに関する情報を処理し、ひいては国家が如何に社会を統制したかを解明する道具となる。
様式論的特徴への注目は、永田英正氏による居延漢簡の簿籍の集成に方法論的に負う所が大きい。永田氏の集成は、各資料の内容的分析よりも形式的解析を優先するものである。簡牘の記載内容に目を奪われてしまうと、伝世文献から得られた「常識」で理解できる簡牘のみを掻い摘んで消化し、極めて断片的で分かりにくい文書簡牘の大半を理解せずに放置することになりかねない。それに対し、特徴的文言や文字の配置などの様式論的特徴や出土地を基準に簡牘を分類し、同類の簡牘を一か所に集めることは、より正確な解読を促進するのみならず、極めて小さな断片についてもその属性を見極め史料として活用することを可能にする。つまり、形式的分析を基軸とする様式論的分類は、記載内容が一見して解読不可能な小さな断片までも広く拾い上げるから、文書簡牘を十全に「史料化」する参照体系であるといえる。
永田氏の方法論は、籾山明氏により発展的に継承され、簡牘の「ライフサイクル」を復元する「簡牘の生態学的研究」に高められた。さらに、髙村武幸氏は、簡牘集成の新たな実践事例として、西北漢簡に対する全体的な形態分類と機能分類を行った。本訳注稿は、その中でも機能分類体系を、里耶秦簡に則した文書学的様式分類に作り替え、その分類に従って原文の釈文を配置した。また、日本語の読み下し文は、文書ごとに、文書様式の特徴を可視化する表形式に整えて表示した。
なお、様式分類の骨子(細目は多く省略)はこちら(展開する/折りたたむ)からご覧いただける。3 HTML形式の資料庫構想の釈文ファイルにおいてアンカーとして用いた記号を含めた詳細な一覧表はyoshikibunrui.xlsxをご参照ください。
|
〇文書 |
〇一往来文書 |
〇一甲敢言之類 |
|
〇一乙敢告類 |
||
|
〇一丙移類 |
||
|
〇一丁謂類 |
||
|
〇一戊告類 |
||
|
〇一己下類 |
||
|
〇一庚卻類 |
||
|
〇一辛追類 |
||
|
〇一壬省略類 |
||
|
〇一不明 |
||
|
〇二証明文書 |
〇二甲出納証明 |
|
|
〇二乙辞 |
||
|
〇二丙鞫 |
||
|
〇二丁劾 |
||
|
〇二戊爰書 |
||
|
〇二己題/探 |
||
|
〇二庚診 |
||
|
〇二辛負(責券) |
||
|
〇二壬自言 |
||
|
〇二癸不明 |
||
|
〇三其它文書 |
〇三甲書信 |
|
|
〇三乙謁 |
||
|
〇三丙刺 |
||
|
未詳 |
||
|
一簿籍 |
一一表題類 |
一一甲表題簡 |
|
一一乙見出簡 |
||
|
未詳 |
||
|
一二本文類 |
||
|
一三末尾類 |
一三甲末尾簡 |
|
|
一三乙小計簡類 |
||
|
一四複合簿籍 |
作徒簿 |
|
|
郵書刺 |
||
|
身分情報 |
||
|
受令 |
||
|
伐閲 |
||
|
計 |
||
|
課 |
||
|
志 |
||
|
録 |
||
|
副 |
||
|
…… |
||
|
二書籍 |
二一思想等作品 |
|
|
二二実用書 |
式 |
|
|
律令 |
||
|
数書 |
||
|
医書 |
||
|
里程表 |
||
|
其它 |
||
|
二三個人的書付 |
質日 |
|
|
習字 |
||
|
三表示札 |
三一付札(楬) |
一〇型 |
|
一一型 |
||
|
三二表示板 |
||
|
四封緘簡牘 |
四一文書類 |
遷陵 |
|
廷 |
||
|
或遝 |
||
|
伝 |
||
|
尉 |
||
|
郷 |
||
|
庫 |
||
|
倉 |
||
|
少内 |
||
|
司空 |
||
|
…… |
||
|
四二物品類 |
||
|
五不明 |
様式分類への強いこだわりは、先述した先行研究から触発されたものであるので、是非以下の関連著作を参照されたい。また、ワードファイルを開いた際は、是非様式分類を反映したナビゲーションバーも積極的に活用されたい。
問題点
ワードファイルの問題点
様式分類の問題点
上記の問題点に拘らず、釈読や読み下し文には幾分参照価値があるように思われる。まだ執筆途上にあり、校正も行われていないから、本来公開を憚らざるを得ないが、ご関心のある方は訳注稿ファイル(2022年1月時点)をご参照ください。引用していただく際は、出典を次のように表記していただければ幸いである。
なお、上記の訳注稿ファイルは、概ね『里耶秦簡(壹)』を対象とした共同史料講読を終えた時点での見解を反映しており、『里耶秦簡(貮)』については未整理のままとなっている部分が多い。里耶秦簡に関する基礎資料としては次の書籍を参照した。その他の個別参考資料は訳注稿ファイルの中に参照指示がある。