ヒンディー語・ウルドゥー語の語彙属性自動解析 (2)
Etymological Analysis of Hindi and Urdu Words
ヒンディー語(デーヴァナーガリー文字)とウルドゥー語(アラビア文字)の語句を、形態素レベルで、辞書の見出し語形と接辞に自動解析します。解析に成功した見出し語形に対し語源情報を付加して表示するシステムです。このシステムは、昨年(2015年度)の同名プロジェクトの成果をさらに向上させたものです。 |
This device aims at analyzing Hindi/Urdu words morphologically and getting their headword forms along with suffixes. Final output contains the etymological information about each headword produced successfully. Users are simply requested to input Hindi in Devanagari and Urdu in Perso-Arabic script respectively. The device is a revised and enlarged one developed under the 2015 project of the same title. |
|
下の画像は、このシステムが解析結果を出力した場合の例です。 【入力】向かって左側の枠の中に ヒンディー語(Hindi) あるいは ウルドゥー語(Urdu) を入力します。別のテキストからのコピーペーストでもかまいません。下の例からわかるように入力する語形に制限はありません。文でも構いません。ただし一度に入力する量は10行以内程度にしてください。 【選択】なお画面上部にある resources: は、ヒンディー語であれば h_etym_20170331 を、 ウルドゥー語であれば u_etym_20170331 を選択してください。 【出力】入力と選択を確認した後、画面中央にある矢印をクリックします。解析結果は向かって右側の枠の中に表示されます。 【語源情報】 {etym{ と }etym} に挟まれた部分が語源情報です。たとえば、 {etym{=Skt.}etym} はサンスクリット語と同じ(つまりサンスクリット語からの借用)であることを示します。 {etym{=Pers.(←Arab.)}etym} はアラビア語から借用されたペルシア語と同じ(つまりペルシア語からの借用)であることを示します。 【辞書】解析に使用されている現在の辞書の大きさは見出し語ベースに換算してヒンディー語では約1万2千語、ウルドゥー語では約7千語です。活用変化も解析対象になるので、実際にカバーする語形は、見出し語の数倍(名詞など)から数百倍(動詞句など)になります。入力された語形が、辞書がカバーしていない語形や誤った語形の場合は、解析はされず入力語形がそのまま出力されます。 |
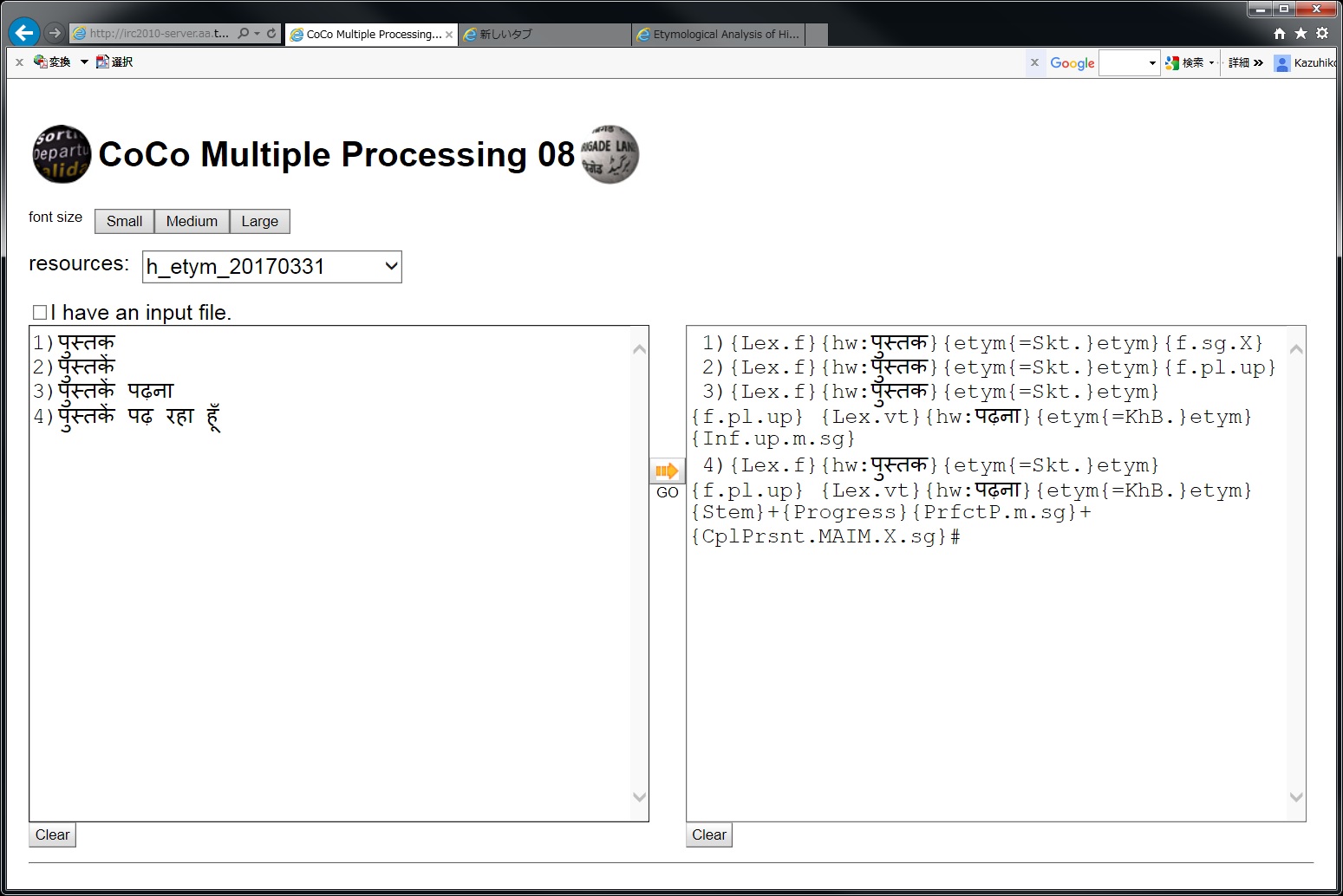 解析結果の{etym{}etym}の中が語源情報です。
解析結果の{etym{}etym}の中が語源情報です。